· PhysicalAI · 3 min read
Understanding Action Chunking with Transformers (ACT): A Simple Guide
Action Chunking with Transformers (ACT) combines the representational strength of autoencoders with the contextual modeling of transformers, producing compact latent variables that generate coherent action sequences.

Action Chunking with Transformers (ACT) is not one of the standard Vision-Language-Action (VLA) models, but it is the imitation learning policies trained from scratch that contributed physical ai ecosystem. Its input is robot current state and image as condition, and the output is 50 continuous action chunk.
Autoencoder, Variational Autoencoder, and Conditional VAE
An Autoencoder (AE) compresses input data into a latent representation and then reconstructs it.
It is mainly used for feature extraction, dimensionality reduction, noise reduction, and input structure learning.
Here, (z) is the compressed latent vector.
A Variational Autoencoder (VAE) extends the AE by modeling the latent space as a probability distribution rather than a single point.
The encoder produces the parameters (\mu) and (\sigma) of a Gaussian distribution, from which a latent vector (z) is sampled.
This regularization enables smooth and continuous latent spaces, allowing both reconstruction and generation of new samples.
A Conditional VAE (CVAE) further extends the VAE by introducing a condition (y) (e.g., context, goals).
Structure of ACT
ACT employs a CVAE to learn robot policies.
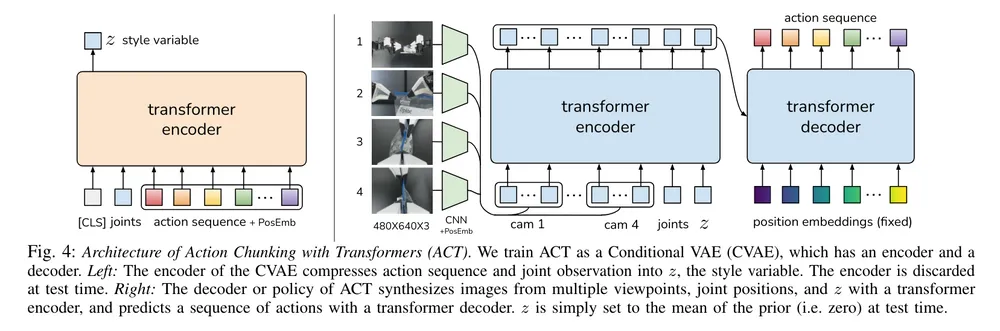
- Encoder: Takes the current state (e.g., joint positions) and encodes it into a latent distribution (Z) using a transformer.
- Conditioning: Contextual information such as sensory inputs or goals (here, four 480×640 images) conditions the latent space.
- Decoder: Uses a transformer to reconstruct or predict future action sequences from the latent representation.
To break this into two parts:
CVAE Encoder
Encodes an action sequence into a latent distribution (mean and variance):CVAE Decoder
Samples from the latent space and predicts the action sequence conditioned on context:
Recall) Transformers
Transformers differ from recurrent networks (RNNs, LSTMs) by processing input sequences in parallel while still capturing long-range dependencies.
- Query (Q): Representation of the current token or state.
- Key (K): Encoded representations of all tokens.
- Value (V): Contextual embeddings carrying semantic content.
The attention mechanism computes relevance between queries and keys, then aggregates values accordingly:
This enables selective recall of relevant past information when generating the next action.
Multi-Headed Attention
Instead of a single attention map, transformers compute multiple attention heads in parallel. Each head captures different relational patterns:
For example, GPT-3 uses 96 heads, providing highly diverse contextual perspectives.
Encoder Layer
The encoder learns how tokens relate to one another within a sequence. Each layer consists of:
- Input Embedding – mapping inputs to vectors
- Positional Encoding – preserving order information
- Multi-Head Self-Attention – capturing inter-token dependencies
- Feed-Forward Network (FFN) – nonlinear feature transformation
This stack is repeated across multiple layers, producing progressively higher-level representations of the input sequence.
Decoder Layer
The decoder generates output sequences step by step. Each layer consists of:
- Masked Multi-Head Self-Attention – prevents the model from attending to future tokens during generation
- Cross-Attention – connects encoder outputs to the decoder’s state
- Feed-Forward Network – nonlinear transformation
- Linear Projection + Softmax – produces the probability distribution for the next token
- Autoregressive Generation – predicted tokens are fed back until an end-of-sequence token is produced
Summary
ACT leverages the compression power of CVAEs with the contextual modeling of transformers. By chunking sequences into latent actions and decoding them under context, ACT can:
- Predict future behaviors
- Reconstruct plausible trajectories
- Generate new action patterns
This makes it a powerful framework for robotics, control, and other sequential decision-making tasks where both memory and adaptability are critical.



