· PhysicalAI · 4 min read
Understanding OpenVLA: A Simple Guide
OpenVLA is a 7B open-source VLA model built on Llama2 + DINOv2 + SigLIP, trained on 970k demos, achieving stronger generalization and robustness than closed RT-2-X (55B) and outperforming Diffusion Policy.

Motivation
- In natural language processing and computer vision, the dominant paradigm is clear:
- Pretrain a large-scale foundation model on massive data.
- Apply fine-tuning or zero-shot inference on downstream tasks.
- Robotics, however, has historically struggled to adopt this recipe. Real-world data is scarce and expensive to collect.
- But recent progress shows that scaling works here too:
- Open X-Embodiment Dataset: 2M+ episodes, 20+ robot embodiments, aggregated from 20+ institutions.
- RT-2 and RT-2-X: Introduced the term Vision-Language-Action (VLA) by adapting pretrained VLMs for robotics.
- Other models (RFM-1, RoboFlamingo, LEO, 3D-VLA) followed — but they remain closed-source or trained only on simulated data.
- However, these models are all nor a open-source, large-scale, real robot foundation model(simulation-only).
Project Goals
OpenVLA goals are:
- Develop a strong open-source VLA model
- Trained on large-scale real robot data
- Provides a generalist policy capable of controlling diverse robots out-of-the-box
- Enable efficient fine-tuning for downstream tasks
- Using parameter-efficient techniques, so researchers with limited compute can adapt OpenVLA
- Release everything openly
- Pretraining code, fine-tuning framework, model weights, and data mixtures
Architecture
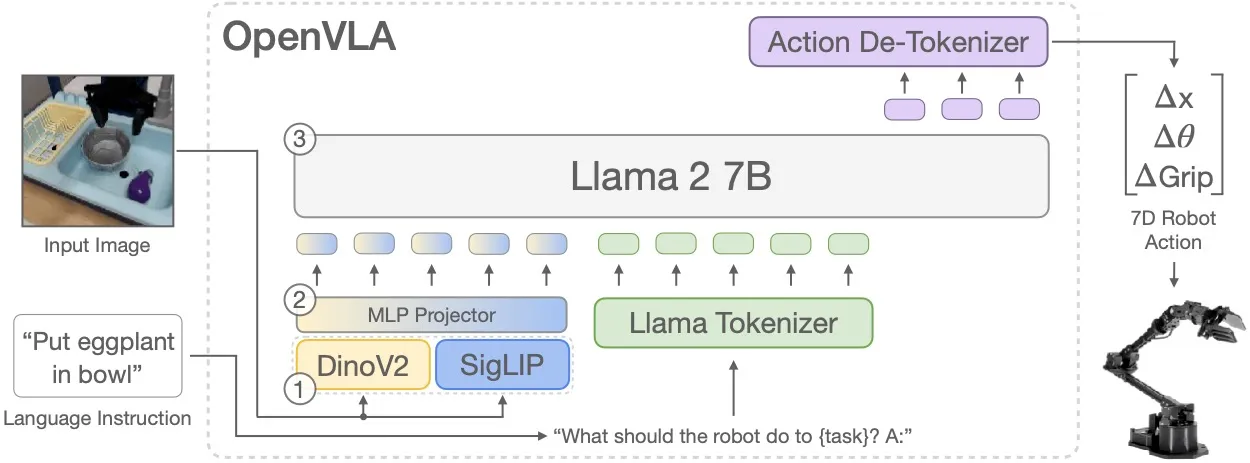
OpenVLA adopts a fully end-to-end architecture that maps visual observations and language instructions directly to robot actions. Unlike modular methods such as Octo, which combine separately trained encoders and decoders, OpenVLA fine-tunes the entire vision–language backbone jointly for action prediction.
Each input image is processed independently by two complementary vision encoders. SigLIP provides semantic alignment with language, while DINOv2 captures spatial reasoning ability. Their feature maps are concatenated channel-wise and projected through a two-layer MLP into the language embedding space. This preserves both semantic grounding and fine-grained spatial structure, producing a rich multimodal representation for downstream reasoning.
The fused vision features are combined with a Llama 2 (7B) backbone through the Prismatic VLM design, which integrates multi-resolution representations. In this way, OpenVLA treats robot control as a next-token generation problem, following the same principles that power large-scale language models.
Model Training
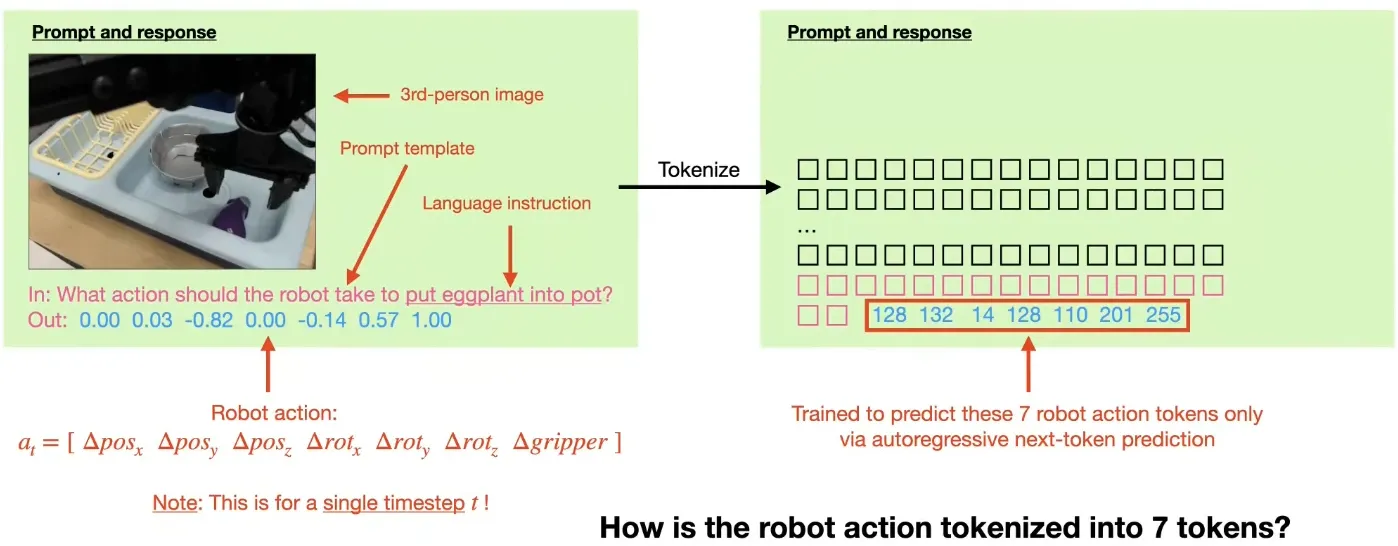
Robot actions are represented as tokens by discretizing each continuous action dimension into 256 bins, based on the 1st–99th percentile of the training data distribution. For an (N)-dimensional action vector:
These discretized values are mapped to reserved tokens in the Llama tokenizer, effectively extending the vocabulary with robot actions. Once embedded as tokens, actions are predicted autoregressively using the same mechanism as language modeling. The training objective is the standard cross-entropy loss applied to action tokens:
where (x) denotes the fused image features, (\ell) the language instruction, and (a_t) the action token at time step (t).
Training was performed on 970,000 demonstrations from the Open X-Embodiment dataset, which spans more than 20 different robot embodiments. This large-scale, diverse dataset provides the foundation for OpenVLA’s strong zero-shot performance and adaptability across tasks and platforms.
Experiments
1. Out-of-the-Box Evaluation
OpenVLA was tested without fine-tuning on diverse unseen tasks:
- Visual generalization: handling new object appearances
- Motion generalization: performing trajectories not seen in training
- Physical generalization: adapting to new robots and embodiments
- Semantic generalization: unseen tasks, insturctions
2. Fine-Tuning Evaluation
With lightweight fine-tuning, OpenVLA quickly adapts to specific robots and tasks, showing strong performance even with limited new data.
3. Parameter-Efficient Fine-Tuning Methods
- Last Layer Only (▼): Fine-tune only LLM’s final layer → poor performance
- Frozen Vision (▼): Freeze vision encoder, fine-tune LLM → significantly worse even when training entire LLM backbone
- Sandwich Fine-Tuning (▲): Fine-tune vision encoder + LLM last layer only → strong performance with moderate compute
- LoRA (Low-Rank Adaptation) (▲): Most effective approach - LoRA rank=32 updates only 1.4% of parameters nearly matches full fine-tuning
4. Inference-Time Quantization for Limited GPU Memory
- 4-bit quantization still maintains 71.9% success rate
- it uses 7GB VRAM (while 16.8GB for bfloat16)
- it preserves performance while cutting memory needs, enabling use on modest GPUs.
Design Decisions & Insights
- Fine-tuning the vision encoder (vs. freezing) crucial for robotic control.
- Higher image resolution (384px vs. 224px) adds 3× compute without performance gains.
- Training required 27 epochs, far more than typical VLM runs, to surpass 95% action token accuracy.
Limitations
- Supports only single-image observations (no proprioception, no history).
- Inference throughput (~6Hz on RTX 4090) insufficient for high-frequency control (e.g., ALOHA at 50Hz).
- Success rates remain below 90% in challenging tasks.
- Open questions:
- Impact of base VLM size on performance.
- Benefits of co-training with Internet-scale data.
- Best visual features for VLAs.
Summary
OpenVLA represents the first open-source VLA foundation model trained on real robot data. It bridges the gap between vision-language models and robotics, enabling:
- Almost first open-source generalist VLA with strong performance.
- Scalable end-to-end training pipeline (action-as-token).
- Demonstrates LoRA + quantization for consumer-grade GPU adaptation.
- Provides code, checkpoints, and data curation recipes to support future research.
By openly releasing weights, code, and data, OpenVLA sets the stage for the next era of generalist robotic policies.



