· PhysicalAI · 2 min read
Understanding Diffusion Policy: A Simple Guide
Diffusion-based models such as DDPM and their use in policy learning rely on denoising mechanisms, UNet architectures, and structured action representations to capture complex sequential behaviors.

DDPM: Denoising Diffusion Probabilistic Models
The core idea of DDPM is to gradually corrupt data with Gaussian noise and then train a model to reverse this process, recovering the original signal.
(where (x_0) is the clean sample, (x_t) is the noisy version at timestep (t), and (x_T) approaches pure white noise.)
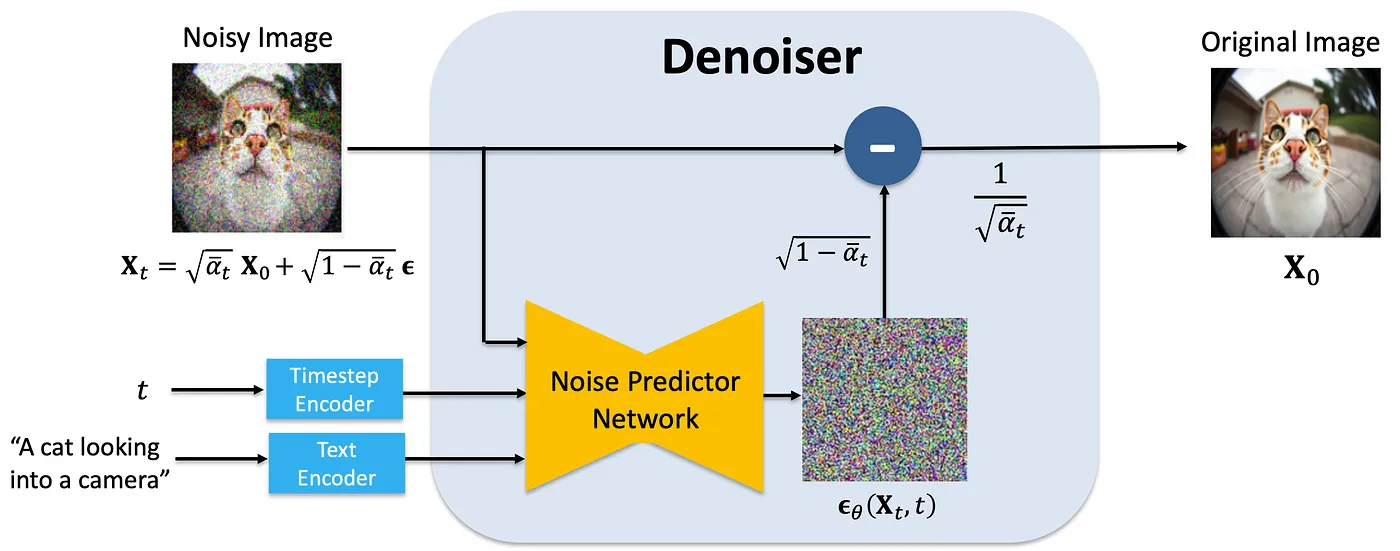
The denoising model learns to predict the noise at each step, so that the reverse process can be expressed.
But here is denoiser, we can use ‘Noisy trajectory’ instead of ‘Noisy Image’ to get denoised trajectory and put image instead of instruction and using Resnet18 instead of ‘Text Encoder’ to use this model as a diffusion policy.
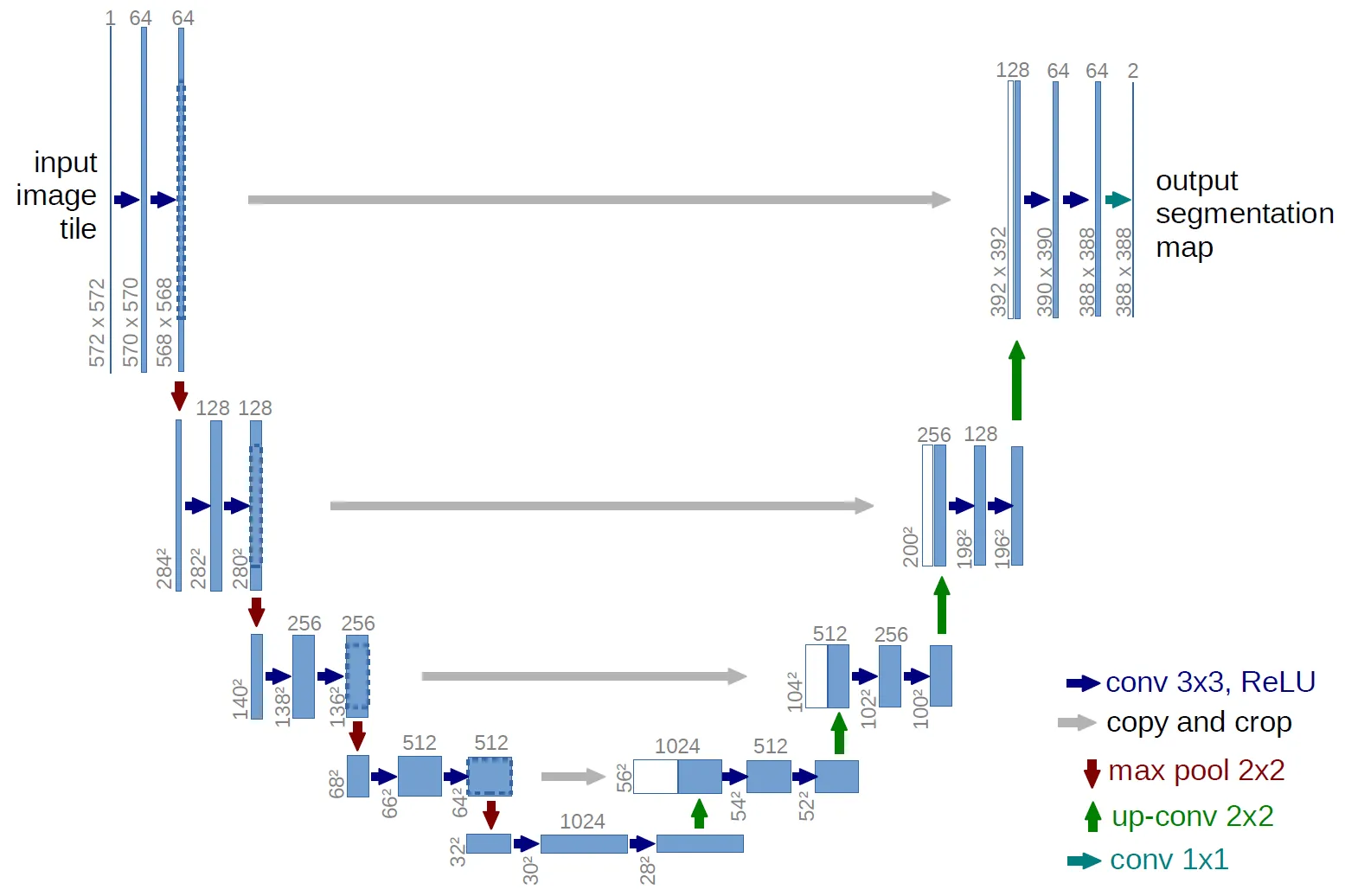
UNet Architecture
The noise predictor network in DDPM is typically a UNet, a convolutional encoder–decoder with skip connections.
- Encoder: progressively downsamples the input to extract hierarchical features.
- Decoder: upsamples and reconstructs, combining semantic and spatial information.
This structure is effective for tasks requiring high-resolution outputs, such as segmentation, super-resolution, and diffusion-based generation.
The training objective often uses mean squared error (MSE) between predicted and true noise:
Features
Diffusion Policy applies the denoising diffusion process to policy learning from demonstrations. Instead of reconstructing images, the model generates action sequences.
Key characteristics:
- Policy learning from demonstrations: imitation learning.
- Supervised regression: a supervised learning setup where the output consists of continuous values.
- Sequential correlation: captures temporal dependencies in robot actions.
- Multimodal distribution: allows sampling diverse but plausible actions.
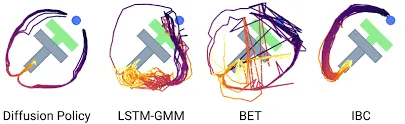
- Action representations: how the policy outputs are structured (e.g., Gaussian mixtures, quantized actions).
- Implicit policies: leverage the diffusion process to generate actions step by step, without explicit reward optimization.
Structure of Diffusion Policy
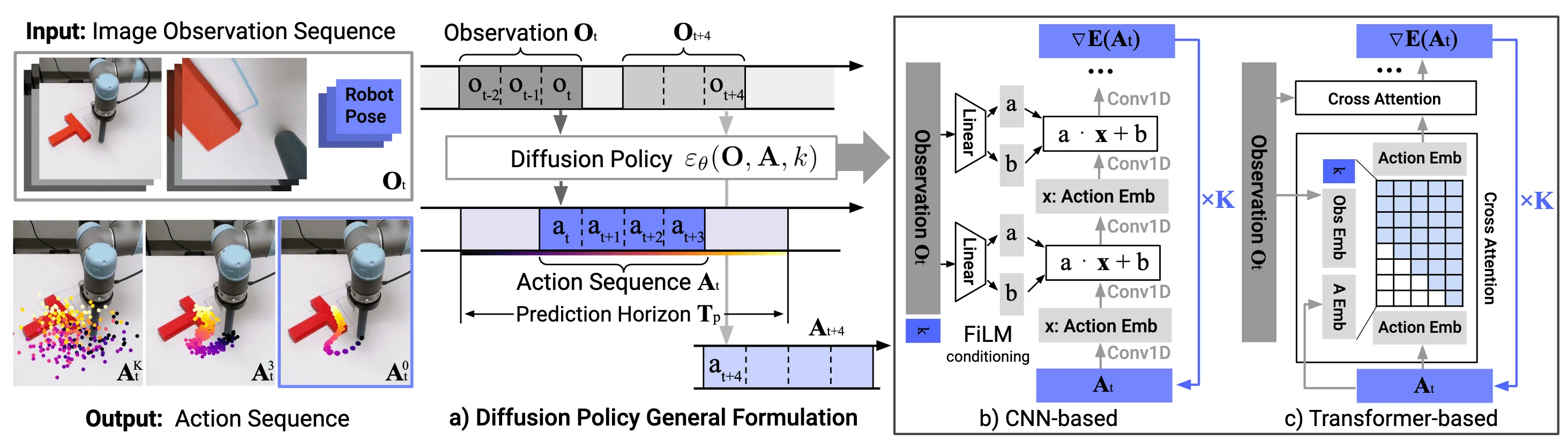
The model takes multi-view camera observations (top camera, wrist camera) and robot pose as input.
The denoising network (ε_θ) is implemented using either a ResNet-based CNN or a time-series diffusion Transformer.
The output is an action sequence ( A_t ) over the prediction horizon.
Key aspects:
- Score function gradient: learns the gradient of the log density, guiding the denoising process.
- Stochastic Langevin dynamics: applied at inference time to sample from the learned policy, improving stability compared to direct energy-based approaches.
Summary
- DDPM: transforms white noise into structured outputs by iterative denoising.
- UNet: the backbone architecture for noise prediction.
- Diffusion Policy: applies diffusion modeling to sequential decision-making, enabling robust imitation of complex behaviors.
Together, these approaches provide a powerful framework for learning policies in robotics and control using probabilistic generative models.



