· PhysicalAI · 3 min read
Understanding π₀: A Simple Guide
π₀ is an innovative VLA model that combines a vision–language backbone with an action expert module and flow matching, producing continuous action sequences from natural language and images.

Introduction
π₀ is a Vision–Language–Action (VLA) model that treats robot control as a sequence modeling problem. It takes natural language commands (e.g., “pick up the apple”) and visual observations as inputs, and produces robot actions as outputs. Unlike models that predict only single-step actions, π₀ generates continuous chunks of 50 actions, enabling smooth trajectories rather than discrete movements.
Architecture
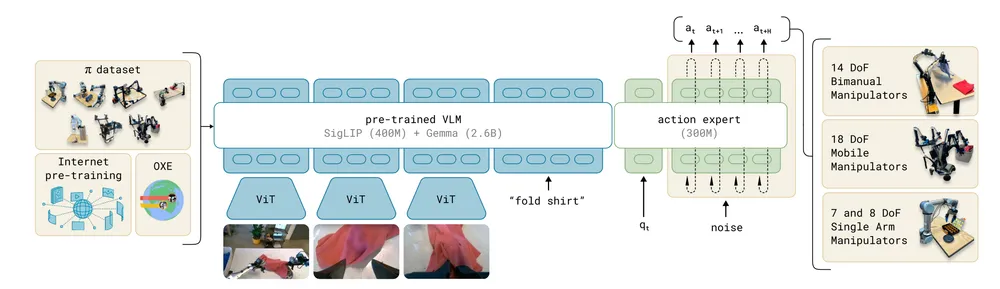
The architecture consists of two major components:
Vision–Language Backbone (VLM)
Inputs include natural language instructions and images.- Language is tokenized into embeddings.
- Images are processed with a vision transformer (e.g., CLS token captures global image meaning).
- The outputs are projected into a shared token space, producing query–key–value (Q, K, V) representations.
Action Expert
This module specializes in robot states and actions.- Input: the robot’s current state and noisy action samples.
- Backbone: a transformer initialized from Gemma.
- Output: action chunks over a prediction horizon.
The key design choice is to freeze the VLM weights (already pretrained on Internet-scale data) and only fine-tune the Action Expert, which adapts the model to physical actions.
Flow Matching
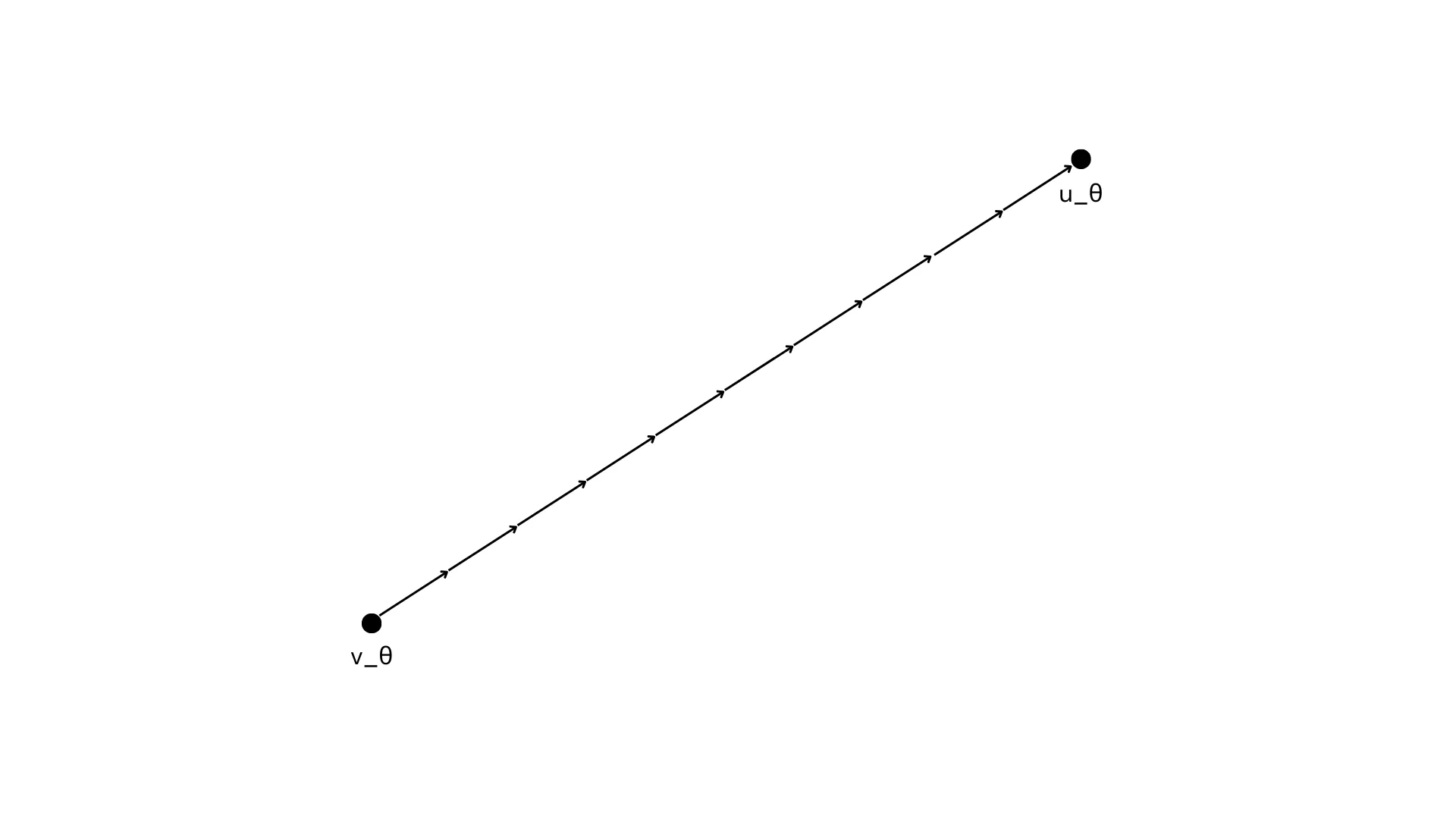
Action generation in π₀ is modeled with flow matching, a variant of diffusion-based learning.
A noised action vector is created as:
where:
- A_t = Action vector
- ε = Gaussian noise
- τ in [0,1] = noise scale
( for example, if τ=0, the right-hand side is close to the original action vector.)
The model learns to predict the denoising vector field:
The network’s prediction v_θ is trained with an MSE loss:
At inference, since the true (u) is unknown, the system integrates the learned vector field:
using Euler integration with step size δ. For example, with δ = 0.1, the trajectory is refined in 10 steps. Smaller steps improve accuracy but increase compute.
Attention Mechanism
Within the transformer, masked attention ensures that tokens cannot access future information during training:
- Block 1 attends only to itself.
- Block 2 can attend to blocks 1–2.
- Block 3 can attend to blocks 1–3.
This is implemented by adding a mask matrix (M) with -∞ values in forbidden positions:
The mask forces irrelevant connections to zero after softmax.
Putting It All Together
- Inputs: Instruction tokens, image tokens (from VLM), robot state, and noisy actions.
- Fusion: All tokens are mapped into the same embedding space.
- Training: VLM weights are frozen, Action Expert weights are trained via flow matching.
- Outputs: 50 continuous action vectors forming an action chunk, enabling smooth robotic control.
Summary
π₀ integrates language, vision, and action into a unified foundation model for robotics. By combining a pretrained VLM with a trainable Action Expert, and adopting flow matching instead of discrete autoregression, it achieves:
- Continuous high-frequency action generation
- Strong generalization across tasks and embodiments
- A scalable path for instruction-following robots
This approach highlights how ideas from LLMs and diffusion models can be adapted to the domain of embodied AI.



